



HBM should be as attractive an investment as Nvidia or TSMC (maybe more so) but the stocks (SK Hynix, Micron) don’t show that – why not?

Nvidia and AMD launch a new GPU every 2 years. At each generation, higher performance manufacturing (TSMC) and HBM (higher density, higher speed, thinner layers). Hence, cost increase at each generation.
Price and volumes are negotiated 1 year ahead. As SK Hynix says, 2026 production is sold out by mid-25. TSMC and SK Hynix mention that their AI / HBM revenues double in 2025. We should expect another 50-60% in 2026.
So why HBM attracts less interest than Foundry (TSMC) or Design (AMD, AVGO, Nvidia)? Because HBM looks more competitive (it isn’t). Because these firms are still exposed to bad old DRAM and NAND (true). But mostly, investor still think this is a cyclical business – HBM isn’t.
SK Hynix is very very cheap at 5x PEx on a consensus that’s very very low. But you you aren’t a Korean qualified investor, you can’t buy the stock. Next best choice: Micron.
Peaking order: Nvidia - SK Hynix - TSMC , ahead of AMD - Micron.
Background: why HBM?
As we know, the conventional computing architecture is based on the Von Neuman model, which is based on:
a processor, a computing module, a logic unit = a CPU or GPU
linked thru a bridge to
a memory data storage unit = DRAM or HBM
As the processor needs to compute data, or has computed something, it sends this data back and forth to the storage unit. Your computer, smartphone, server work like this. As we know, the bridge is a speed bottleneck that has limited computing power for a long time. The memory data storage unit is also a bottleneck because it runs at a slower speed than the computing unit.
The x86 processors made by AMD, Intel coped with this speed / data transmission problem by adding larger buffers, large amounts of DRAM, some fancy ways of computing (out of order, branch prediction) etc. It all worked out well enough till very large AI models required 100x more data, at much higher speed, and also a different way of computing.
Long story short: the solution to improve the speed / bandwidth problems is to take a blow torch and weld a big amount of memory directly on the processor. This is what this diagram means.
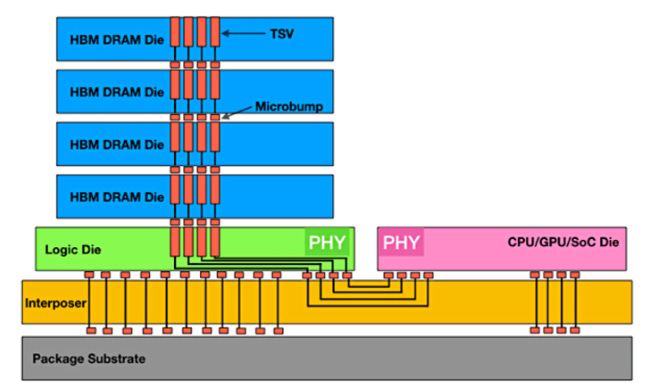
When we say that Nvidia sells GPU, we are referring to 3 things:
a logic computing chip, the GPU itself, designed by Nvidia and made by TSMC
the HBM memory stack, designed and made by SK Hynix
the assembly of this package into a single chip, including all the messy interconnect that you can see in the chart above, that’s called CoWoS made by TSMC.
At each generation, performance and specifications increase very rapidly
We do not know when AI models will have enough computing power. As long as AI models can use more computing power to produce better results that have a higher economic value that justify more investments on new GPU => this story will keep going.
Remarkable fact #1: the cadence of new GPU launch is a lot faster than we’ve ever seen with server or computers, the increase in performance is a lot faster, this is accelerating at each generation like never before.
Remarkable fact #2: the size of demand is increasing with each generation – right? Nvidia’s revenue increase with each new GPU.
Illustration: Nvidia launches a new GPU every 2 years, computing power increases by at least 2x at each generation, a new TSMC node and a new HBM are used.

The speed of this is amazing and it is a problem for the supply chain: development times are long but production time is quite short – if you miss the boat, it’s difficult to catch up.
AMD is on its way to catch up to Nvidia, in terms of performance and roadmap by 2026 (MI400) for at least some use-cases.
Micron is on its way to catch up to SK Hynix with HBM3e (that’s now) and HBM4 (2026).
Samsung is not catching up to SK Hynix and is at least 1 gen and 1 process behind today. By mid-26, it could widen to 2 generations behind.
Intel is not catching up to anybody, Intel doesn’t have any viable AI / GPU solution today.
Samsung and Intel are not catching up to TSMC in terms of manufacturing.
At each generation, the increase in HBM performance is very large (higher price too)
Nothing is easy in semiconductors, so I want to avoid saying that HBM is as hard as or harder than TSMC manufacturing. But certainly, we don’t talk enough about how demanding the HBM roadmap is.
At each Gen, there is either:
a) an increase in density (capacity per die in Gb) which means manufacturing smaller DRAM cells
b) an increase in the number of stacks which means more complicated packaging (TSV, bonding)
resulting in c) very rapid increase in the amount of memory per HBM stack
There is an equally rapid increase in data speed (technically, data rate and bandwidth are different things, but let’s call it speed).
The increase in density and speed require a new manufacturing node. For TSMC we talk about N3 3nm or N2 2nm and for DRAM we have different alphabet pasta: 1Z 1a 1b 1c.
If you’ve read articles on Samsung struggling with 1c, or my article here, or SK Hynix review of the challenges of 1c, this is why we care about the alphabet pasta: it is critical to increasing density and speed. Refer to the last raw in the table below:
It’s going to get worse
Memory industry specifications are made at JEDEC. It’s an industry standard body where, for example, all DRAM makers and all PC makers agree on the next DRAM specifications.
For HBM there is a critical R&D body: KAIST in Korea. KAIST is a University and its TERA Lab (TeraByte Interconnect and Package Lab) is where future HBM specs are made.
The chart below shows that GPU / HBM are going to get a lot lot worse: harder and more expensive.
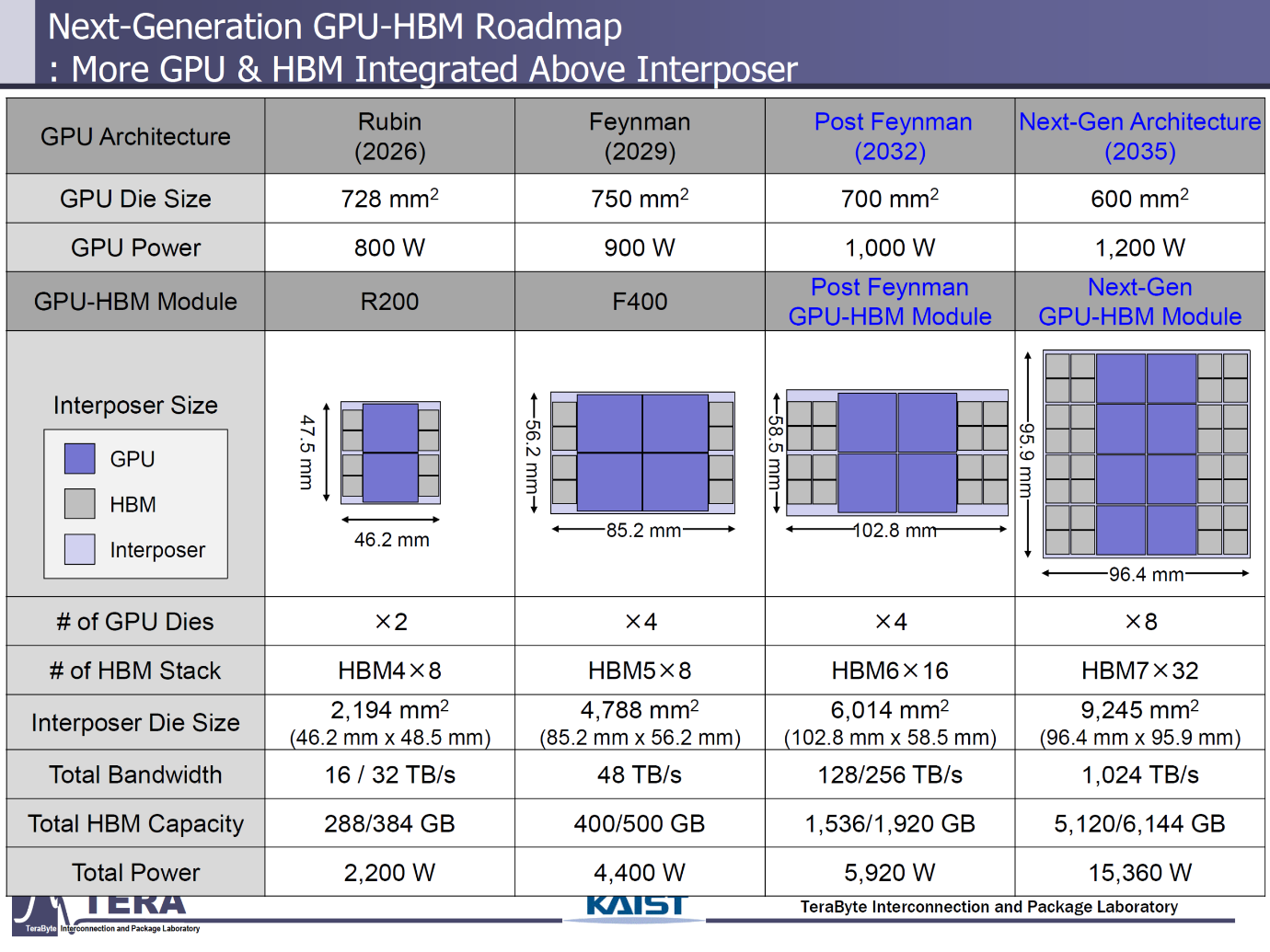
The roadmap to more expensive GPU and HBM is pretty clear. Die size will continue to increase with increase new integration tools (TSMC below), HBM density, speed, bandwidth will continue to increase (KAIST above). The industry is pretty clear and transparent about its roadmap – investors don’t believe it.

HBM Price keeps going up – as fast as TSMC wafer price
Let’s recap. At each HBM generation:
The price per GB is going up (US$ per Gigabyte of DRAM capacity) because:
memory density increase
data speed increase
At each other generation, the number of chips in the stack goes up (but the stack can’t get thicker). This also means that the cost of the HBM stack goes up
more processing to thin the wafers
more packaging, TSV, bonding

This is the mechanics of why HBM price per GB will keep increasing at each generation: higher density, higher speed, thinner layers of DRAM.
The rule of thumb today is: if 1GB of DDR5 costs $3.5 (at the moment that’s the price), then 1GB of HBM3e costs $18-20. So 5% of DRAM volume output (in GB) is equal to 20% of DRAM industry revenues. Volumes double in 2025, or 2.2x. Below is an old TrendForce chart. 2024 estimates are close to reality. TrendForce is now saying that HBM revenues in 2025 will increase 150%, share of revenue ~35-40%.
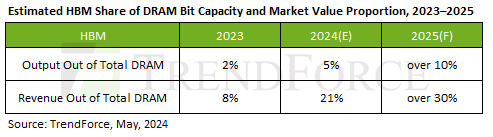
Another way to look at this is: HBM revenues are increasing at the same pace as TSMC AI revenues and AI chip revenues (or a bit faster). There is no major difference between different components: the complete chip, the logic section or the HBM element. Similar growth.

Large divergence in growth expectations
TSMC says:
Even after more than tripling in 2024, we forecast our revenue from AI accelerator to double in 2025.
we forecast the revenue growth from AI accelerators to approach a mid-40% CAGR for the five-year period starting off the already higher base of 2024.
We have enough numbers to derive something like this: TSMC AI revenues were US$13bn in 2024, and will reach US$80bn by 2029. That’s 6.2x.

AMD maintained its estimate of $500bn by 2028, 60% Cagr “or exceeding that”. Using AMD’s chart, it looks like this:
Marvell AI event (PDF here, video here) explained that its Data Center / Accelerators growth opportunity is at ~50% Cagr to 2028. That’s the growth in Addressable Market. CEO suggested that data center revenues can increase 4.4x from 2024 to 28

Firms above give us a range of 45% to 60% growth Cagr to 2028. Just for fun, let’s benchmark that revenue growth for Nvidia. Let’s lower the growth rate Cagr to mid-30% because it’s reasonable to think that HBM controllers and ASICs will grow faster than Nvidia (from a much smaller base). You get this: Nvidia’s data center revenues were US$115bn in 2024, and will reach US$490bn by 2029. That’s 4.2x.

And at the opposite, we have fairly low growth expectations for Memory firms.
Each firm has its own revenue exposure to AI. This will lead to different growth rates. Also, memory firms Micron, SK Hynix have an ~80% exposure to the regular DRAM and NAND memory market, so its not all AI driven bullishness.
But nevertheless, how on earth can Korean analysts forecast 14% revenue growth for SK Hynix in 2026 and 8% in 2027? Micron FY26 maybe ok, but 5% growth in FY27? We have a bunch of ridiculously low forecasts.
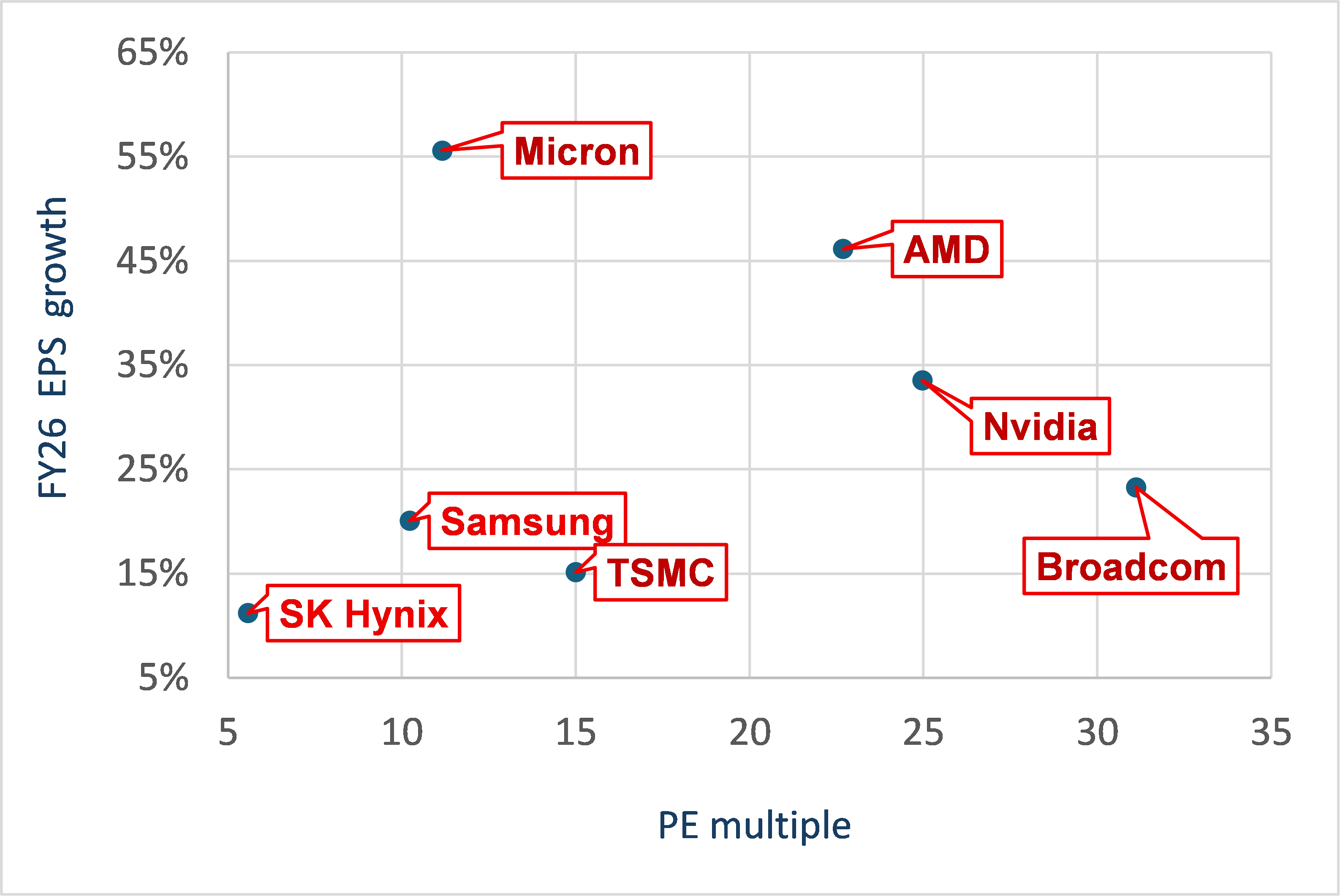
If we look at EPS growth and PE multiple, it’s the same problem but worse:
Forecasts for 2026 are generally low
For 2027 way too low at ~10% or less for Micron, Nvidia, SK Hynix

Map of growth versus valuations
AMD is interesting: high EPS growth as the firm finally sees success in data center GPU, at a reasonable PEx 23x
Broadcom is a weird outlier: very expensive at 31x but not that much growth – less than AMD or Nvidia – why bother?
Micron is interesting: a lot of growth in 26, clearly 27 is too low, for a low PEx 11x
Nvidia is interesting: a lot of growth in 26, clearly 27 is too low, reasonable PEx 25x if you believe that the firm will remain the leader in AI compute with a 60-70% market share
Samsung: lots of problems and not particularly cheap for a firm with management snafu, loss of share in memory, air pockets in consumer elec, etc etc
SK Hynix is the strangest – and most appealing IMO: consensus is ridiculously low, valuations ridiculously low. The stock is still trading like a cyclical memory firm. That’s the biggest disconnect we have here – and the biggest upside potential IMO.
Supply chain charts
If you’re looking for detailed supply chain charts, please go to Jeff C at Semi Vision and here. He’s the best!
